An education that prepares you for the future
The School of Engineering and Computer Science (SOECS) at University of the Pacific is one of California's leading engineering and computer science schools. Engineering and computer science programs are built around a foundation of experiential learning that empowers students to solve problems through innovation and outside-the-box thinking. Most students in SOECS participate in the distinguished cooperative education (CO-OP) program where they can gain industry experience through paid, professional internships that are built into the curriculum.


See the latest issue that showcases the work and success of our students, faculty and alumni.
Our distinguished cooperative education program gives students 'learn and earn' professional internships, built right into the curriculum, with one of our 200+ industry partners worldwide.





We offer a wide range of major and minor degrees, broad availability of student services, and a high success rate of our graduates finding post-graduate employment or education.

Research reinforces classroom knowledge and gives students the opportunity to apply what they have learned. A better understanding and deeper appreciation of the studied material is developed through research, whether in research partnerships with professors, hands-on research in the field, or the required capstone project.
Ranked in the top 20% of all non-doctoral Engineering and Computer Science programs in the country
of all non-doctoral Engineering and Computer Science programs in the country.
Best Undergraduate Engineering Programs, US News and World Report 2021
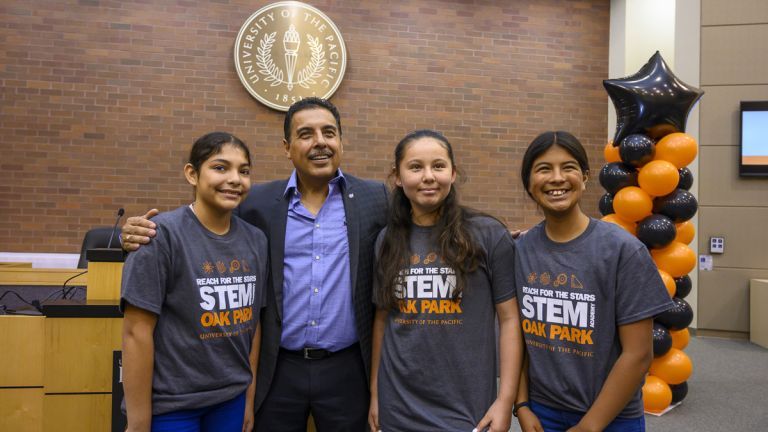
Reach for the Stars STEM Academy
Reach for the Stars (RFTS) 2021 is a virtual STEM academy in Sacramento for rising 7th grade students. RFTS encourages academic achievement and strives to increase college attendance. Registration is open now.

Pacific brings hands-on-learning environment to students’ homes
These kits, which supply necessary lab equipment such as logic analyzers, multimeters and test leads, will bring Pacific’s hands-on-learning environment to students’ homes.

Stockton native named city’s director of public works
Pacific alumna rises through the ranks of Stockton’s public works department